录入文字数据时,计算机手动打字是非常缓慢的。比如图书馆数据库需要把一些资料录入,手动打字慢且错误率高。图片文字识别软件就能把扫描的图片,转化成文字,速度快,出错率低。汉王OCR图片文字识别软件如何识别文字呢?识别文字有什么技巧?下面跟随小编来看看汉王OCR图片文字识别的使用方法。
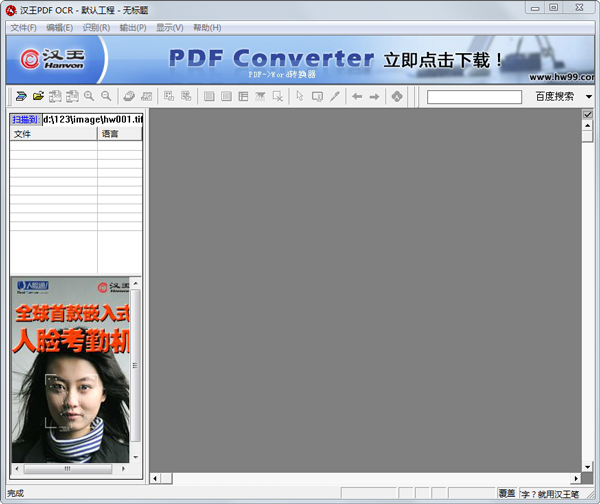
汉王OCR图片文字识别新增打开与识别PDF文件功能,支持文字型PDF的直接转换和图像型PDF的OCR识别,既可以采用OCR的方式将PDF文件转换为可编辑文档,也可以采用格式转换的方式直接转换文字型PDF文件为RTF文件或文本文件。
OCR文字识别技术是什么?
光学字符识别(英语:Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。OCR的概念是在1929年由德国科学家Tausheck最先提出来,并申请了专利。后来美国科学家Handel也提出了利用技术对文字进行识别的想法。国内最早的OCR商业应用是由中国科学家王庆人教授在南开大学开发出来的,并在美国市场投入商业使用。
汉王OCR图片文字识别使用方法
1.在开始菜单中打开OCR软件。
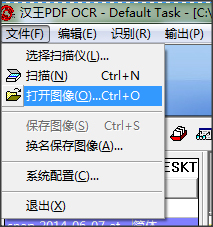
2.点击【文件】-【打开图像文件】,选择一副包含文字的图片。
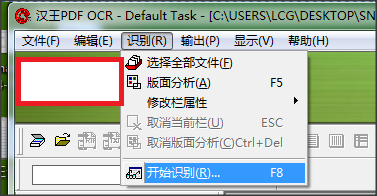
3.点击【识别】-【开始识别】。

4.软件会识别出图片上的文字,可以对一些识别错误的字进行修改。
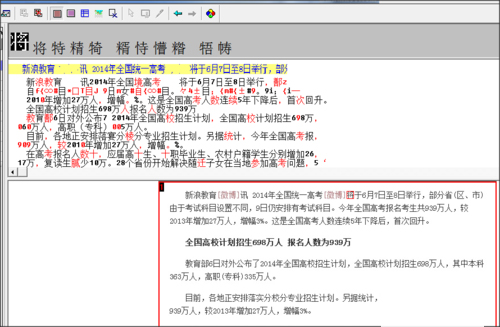
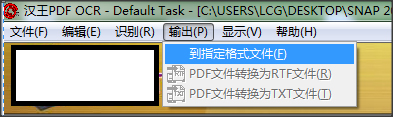
5.修改完成后点击【输出】-【到指定格式】,保存识别出来的文本。
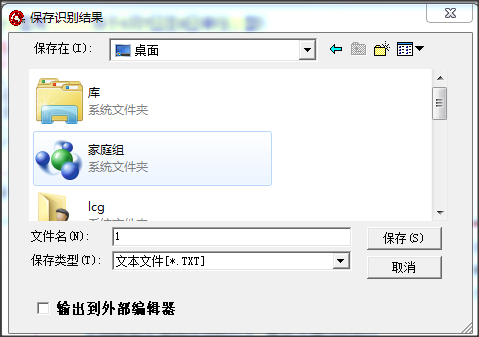
6.可以打开保存的文本,将文本复制到word等软件处进行二次编辑。
OCR文字识别过程
1.图像输入、图像前处理、预识别。
2.图像输入
对于不同的图像格式,有着不同的存储格式,不同的压缩方式,目前有OpenCV、CxImage等开源项目。
3.预处理
主要包括二值化,噪声去除,倾斜较正等。
4.二值化
对摄像头拍摄的图片,大多数是彩色图像,彩色图像所含信息量巨大,对于图片的内容,可以简单的分为前景与背景,为了让计算机更快的、更好地识别文字,我们需要先对彩色图进行处理,使图片只前景信息与背景信息,可以简单的定义前景信息为黑色,背景信息为白色,这就是二值化图。
5.噪声去除
对于不同的文档,对噪声的定义可以不同,根据噪声的特征进行去燥,就叫做噪声去除。
6.倾斜校正
由于一般用户,在拍照文档时,都比较随意,因此拍照出来的图片不可避免的产生倾斜,这就需要文字识别软件进行较正。
7.版面分析
将文档图片分段落,分行的过程就叫做版面分析,由于实际文档的多样性,复杂性,因此,目前还没有一个固定的,最优的切割模型。
8.字符切割
由于拍照条件的限制,经常造成字符粘连,断笔,因此极大限制了识别系统的性能。
9.字符识别
这一研究已经是很早的事情了,比较早有模板匹配,后来以特征提取为主,由于文字的位移,笔画的粗细,断笔,粘连,旋转等因素的影响,极大影响特征的提取的难度。
10.版面还原
人们希望识别后的文字,仍然像原文档图片那样排列着,段落不变,位置不变,顺序不变地输出到Word文档、PDF文档等,这一过程就叫做版面还原。
11.后处理、校对
根据特定的语言上下文的关系,对识别结果进行校正,就是后处理。
文字识别是什么?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。
文字识别一般包括文字信息的采集、信息的分析与处理、信息的分类判别等几个部分。
信息采集:将纸面上的文字灰度变换成电信号,输入到计算机中去。信息采集由文字识别机中的送纸机构和光电变换装置来实现,有飞点扫描、摄像机、光敏元件和激光扫描等光电变换装置。
信息分析和处理:对变换后的电信号消除各种由于印刷质量、纸质(均匀性、污点等)或书写工具等因素所造成的噪音和干扰,进行大小、偏转、浓淡、粗细等各种正规化处理。
信息的分类判别:对去掉噪声并正规化后的文字信息进行分类判别,以输出识别结果。
OCR识别技巧
1.分辨率的设置是文字识别的重要前提。一般来讲,扫描仪提供较多的图像信息,识别软件比较容易得出识别结果。但也不是扫描分辨率设得越高识别正确率就越高。选择300dpi或400dpi分辨率,适合大部分文档扫描。
2. 扫描时适当地调整好亮度和对比度值,使扫描文件黑白分明。
3.选好扫描软件。选一款好的适合自己的OCR软件是作好文字识别工作的基础,一般不要使用扫描仪自带的OEM软件,OEM的OCR软件的功能少、效果差,有的甚至没有中文识别。
4.如果要进行的文本是带有格式的,如粗体、斜体、首行缩进等,部分OCR软件识别不出来,会丢失格式或出现乱码。如果必须扫描带有格式的文本,事先要确保使用的识别软件是否支持文字格式的扫描。也可以关闭样式识别系统,使软件集中注意力查找正确的字符,不再顾及字体和字体格式。
5.在扫描识别报纸或其他半透明文稿时,背面的文字透过纸张混淆文字字形,对识别会造成很大的障碍。遇到该类扫描,只要在扫描原稿的背面附。盖一张黑纸,扫描时,增加扫描对比度,即可减少背面模糊字体的影响,提高识别正确率。
6.一般文本扫描原稿都为黑、白两色原稿,但是在扫描设置时却常将扫描模式设为灰度模式。特别是在原稿质量较差时,使用灰度模式扫描,并在扫描软件处理完后再继续识别,这样会得到较好的识别正确率。
7.遇到图文混排的扫描原稿,首先明确使用的识别软件是否支持自动分析图文这一功能。如果支持的话,在进行这类扫描识别时,OCR软件会自动计算出文本的内容、位置和先后顺序。文字部分可以按照标示顺序正常识别。
8.手动选取扫描区域会有更好识别效果。设置好参数后,先预览一下,然后开始选取扫描区域。
9.在放置扫描原稿时,把扫描的文字材料一定要摆放在扫描起始线正中,以最大限度地减小由于光学透镜导致的失真。同时应保护扫描仪玻璃的干净和不受损害。
10.先“预览”整体版面,选定要扫描的区域,再用“放大预览”工具,选择一小块进行放大显示到全屏幕,观察其文字的对比度,文字的深浅浓度,据情况调整“阀值”的大小,最终要求文字清晰,不浓(文字成团),不淡(文字断笔伐),一般在“阀值”80左右为宜,最后再扫描。
11.用工具擦掉图像污点,包括原来版面中的不需要识别的插图、分隔线等,使文字图像中除了文字没有一点多余的东西;这可以大提高识别率并减少识别后的修改工作。
12.如果要扫描印刷质量稍微差一些的文章,比如说报纸,扫描的结果将不会黑白分明,会出现大量的黑点,而且在字体的笔画上也会出现粘连现象,这两项可是汉字识别的大忌,将严重影响汉字识别的正确率。
以上就是汉王OCR图片文字识别的使用过程。OCR图片文字识别是一项先进的技术,对于资料保存、输入有重要的作用。碰到存档,不要只会拍照保存,你还可以把照片拿去OCR,把文字识别出来保存。关注教程之家,解锁更多软件教程。